

8 Agentic AI Workflows for Enterprises in 2026
There's a gap that's widening fast in enterprise AI teams right now.
On one side: teams that treat LLMs as answer machines, one prompt in, one response out. On the other: teams that have figured out that LLMs are architectural components, and the workflow pattern you choose determines everything about whether your system actually works at scale.
Agentic LLM workflows are not a new concept. But in 2026, the gap between knowing the patterns exist and knowing when to apply which one is where most enterprise AI implementations either hold up or fall apart.
This edition breaks down all 9. How each one works, what it's actually built for, and how to think about them as a decision-maker, not a developer.
Why Workflow Architecture Matters More Than Model Choice
Most AI strategy conversations in boardrooms are still about model selection. GPT-5 vs. Gemini vs. Claude. That's the wrong conversation to be having first.
The model is one component. The workflow pattern is the system. A weak model inside a well-designed workflow will consistently outperform a powerful model used naively. The reverse is rarely true.
What agentic workflow design actually determines:
- Reliability: It is whether the system catches and corrects its own errors
- Speed: whether tasks run sequentially or in parallel
- Cost: how many LLM calls run per task, and whether they're necessary
- Control: how much human oversight is built into the loop
- Scalability: whether the architecture holds when task complexity increases
Choose the workflow first. Then choose the model that fits it.
The 8 Agentic LLM Workflow Patterns
1. Prompt Chaining
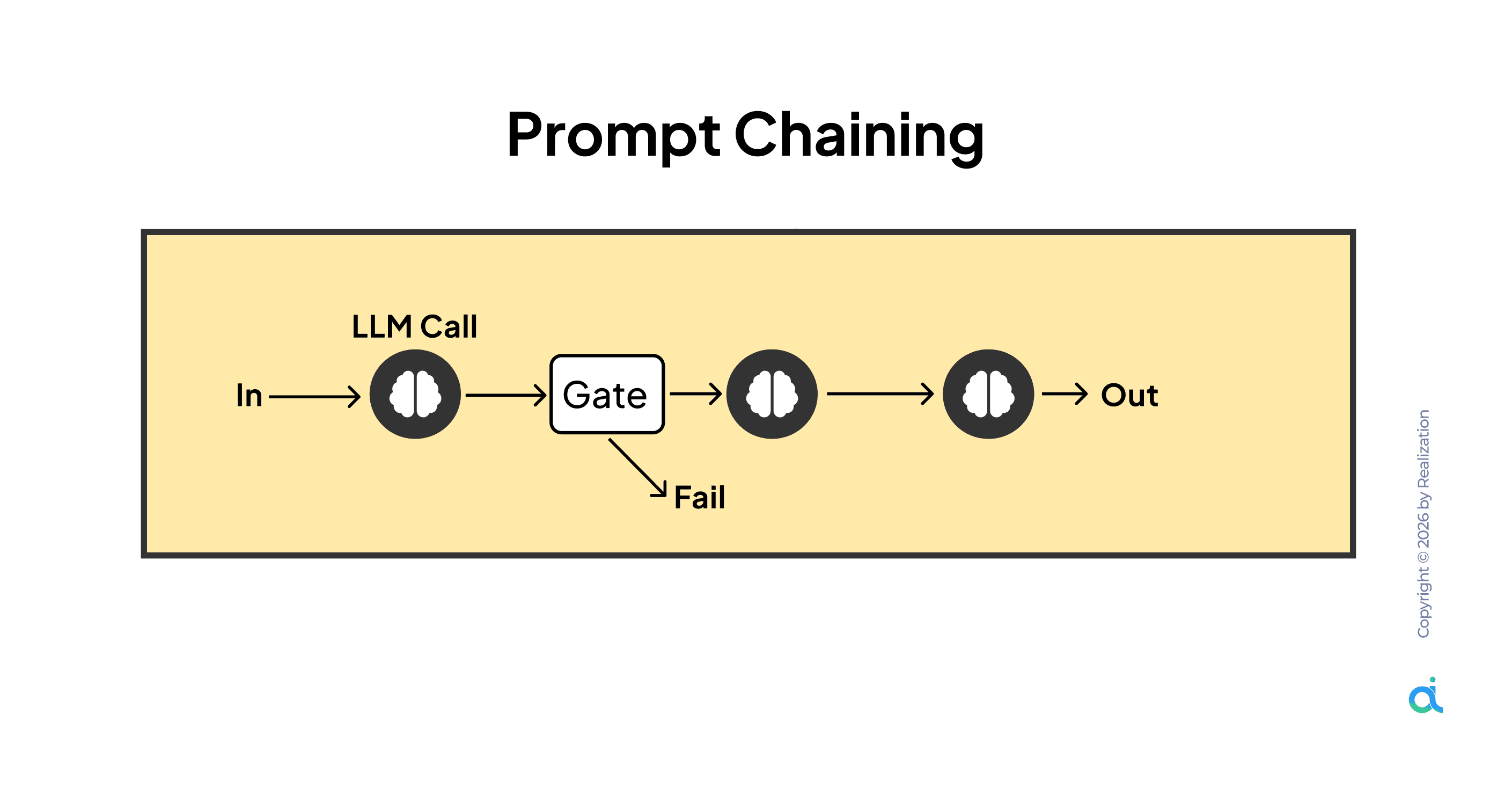
What it is: Breaks a task into sequential steps where each output feeds the next input, with a gate that checks quality before progression.
How it works:
- Input enters the first LLM call
- Output passes through a validation gate. If it fails, the chain stops
- If it passes, the output becomes the input for the next LLM call
- The process repeats until the final output is produced
Best suited for:
- Chatbots with multi-turn logic
- Step-by-step content generation (briefs → drafts → edits)
- Data pipelines requiring structured transformation
- Tool workflows where each step has a dependency on the last
When to use it: When your task has a natural sequence, and each step needs to be validated before the next begins. The gate mechanism is the critical feature; it's what prevents a bad early output from corrupting everything downstream.
When not to use it: When steps are independent of each other. Running sequentially where parallel is possible wastes time and computing resources.
2. Parallelization
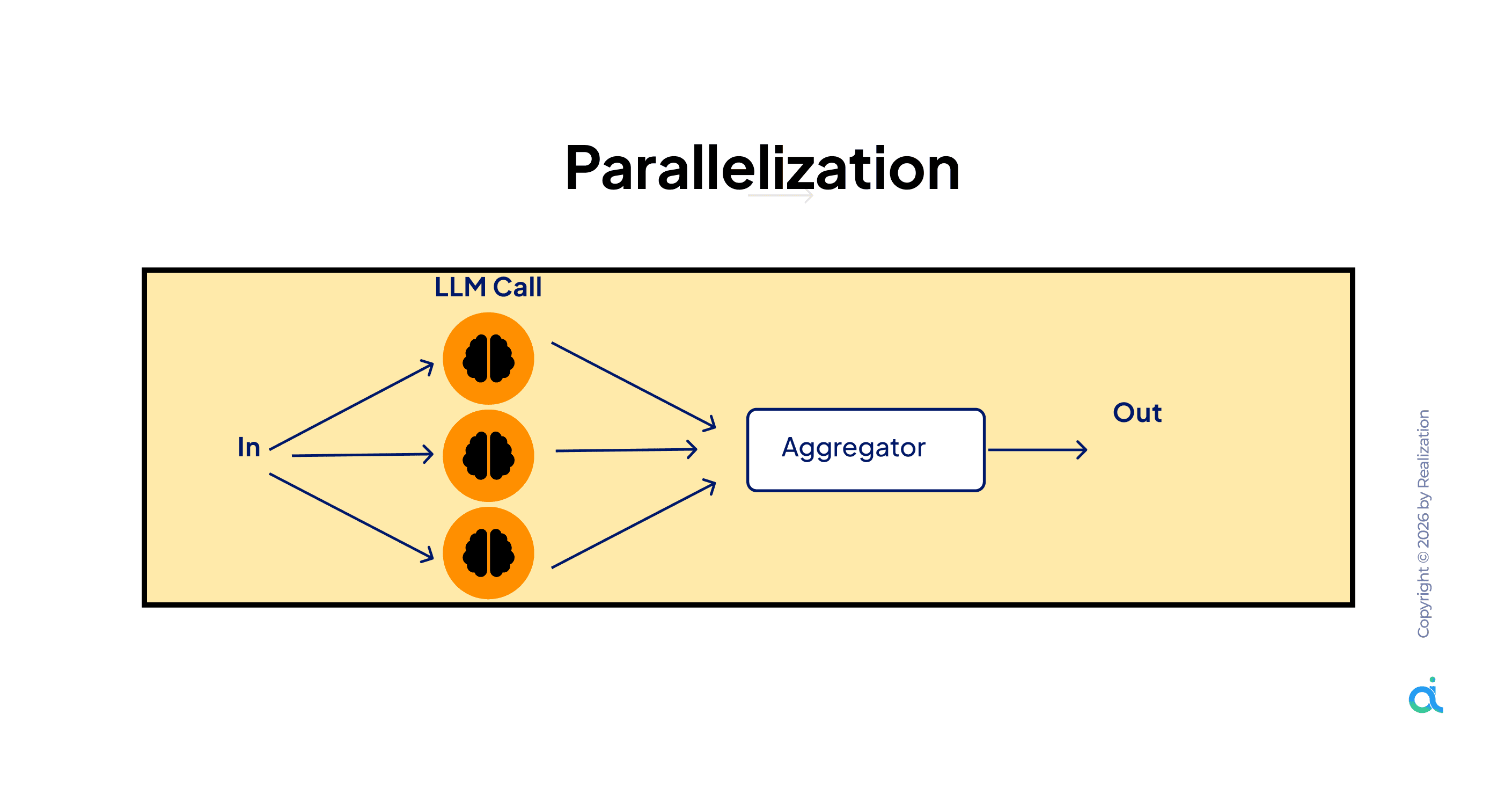
What it is: Runs multiple LLM calls simultaneously on the same input, then aggregates the results into a single output.
How it works:
- Single input is distributed to multiple LLM calls running at the same time
- All calls are completed independently
- An aggregator layer combines and reconciles outputs
- The final consolidated output is produced
Best suited for:
- Faster processing of high-volume tasks
- Bulk evaluations requiring multiple perspectives
- Generating multiple output variations simultaneously
- Guardrail checking, running safety and quality checks in parallel with generation
When to use it: When speed matters and your subtasks don't depend on each other. Additionally, when you require redundancy, you can run the same task through multiple model calls and select the best or most consistent result.
When not to use it: When outputs need to be built sequentially, or when aggregation logic is complex enough to introduce more errors than the parallel calls solve.
3. Orchestrator-Worker
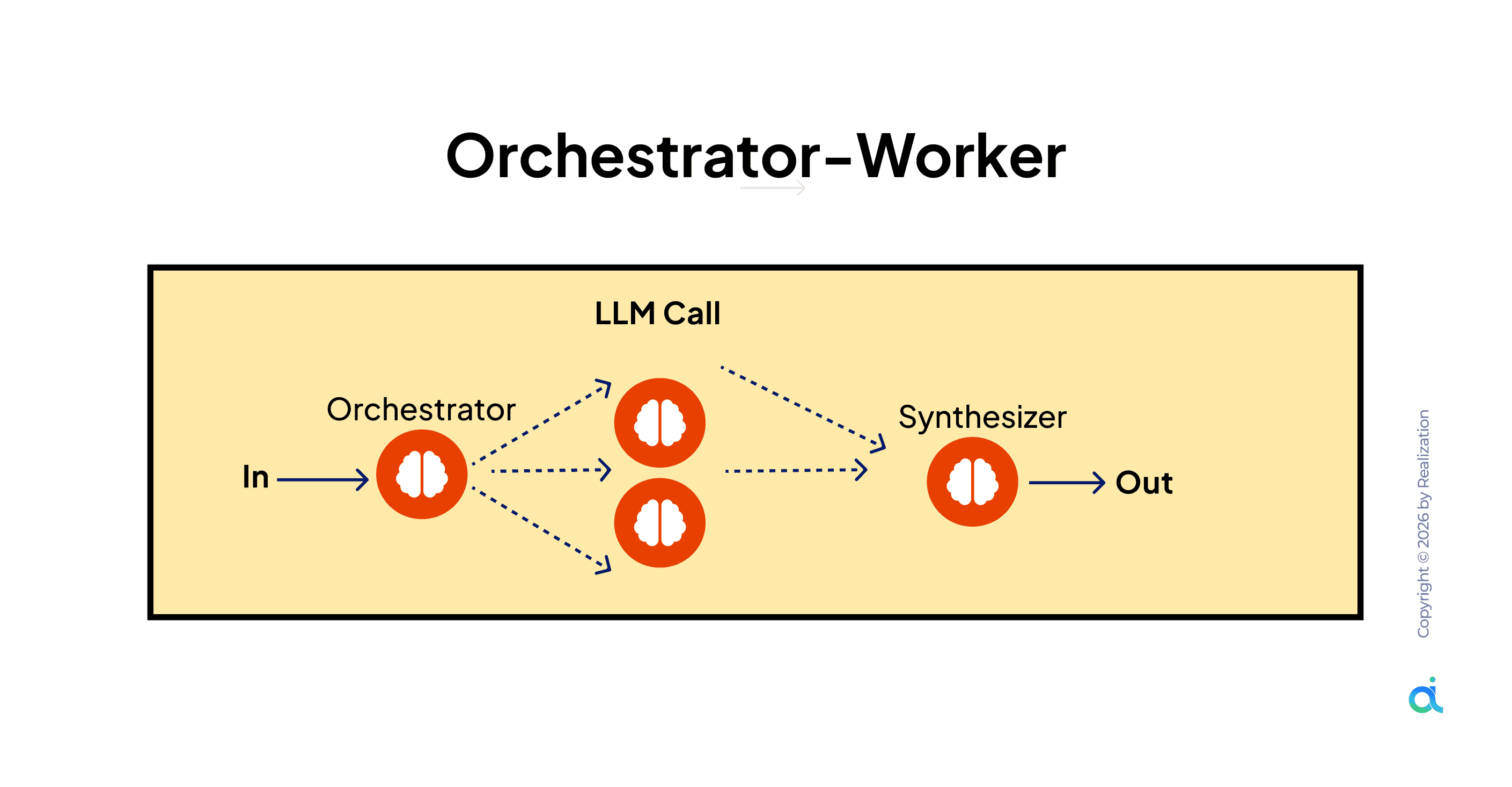
What it is: A main orchestrator agent splits a complex task and assigns subtasks to specialized worker agents, then a synthesizer combines the results.
How it works:
- Input arrives at the Orchestrator
- Orchestrator breaks the task into discrete subtasks
- Subtasks are distributed to Worker agents (specialist or general)
- Workers complete tasks independently
- The synthesizer receives all worker outputs and produces the final result
Best suited for:
- Agentic RAG retrieval across multiple sources simultaneously
- Coding agents working across multiple files or services
- Complex multi-step tasks requiring different types of reasoning
- Multi-agent systems with specialized capabilities
When to use it: When your task is too complex for a single LLM call and decomposes naturally into parallel subtasks. The orchestrator pattern is what Claude Code's parallel agent feature runs on. It's also the pattern behind most enterprise AI pipelines that actually scale.
When not to use it: Simple tasks that don't benefit from decomposition; the orchestrator overhead adds latency and cost without adding value.
4. Router
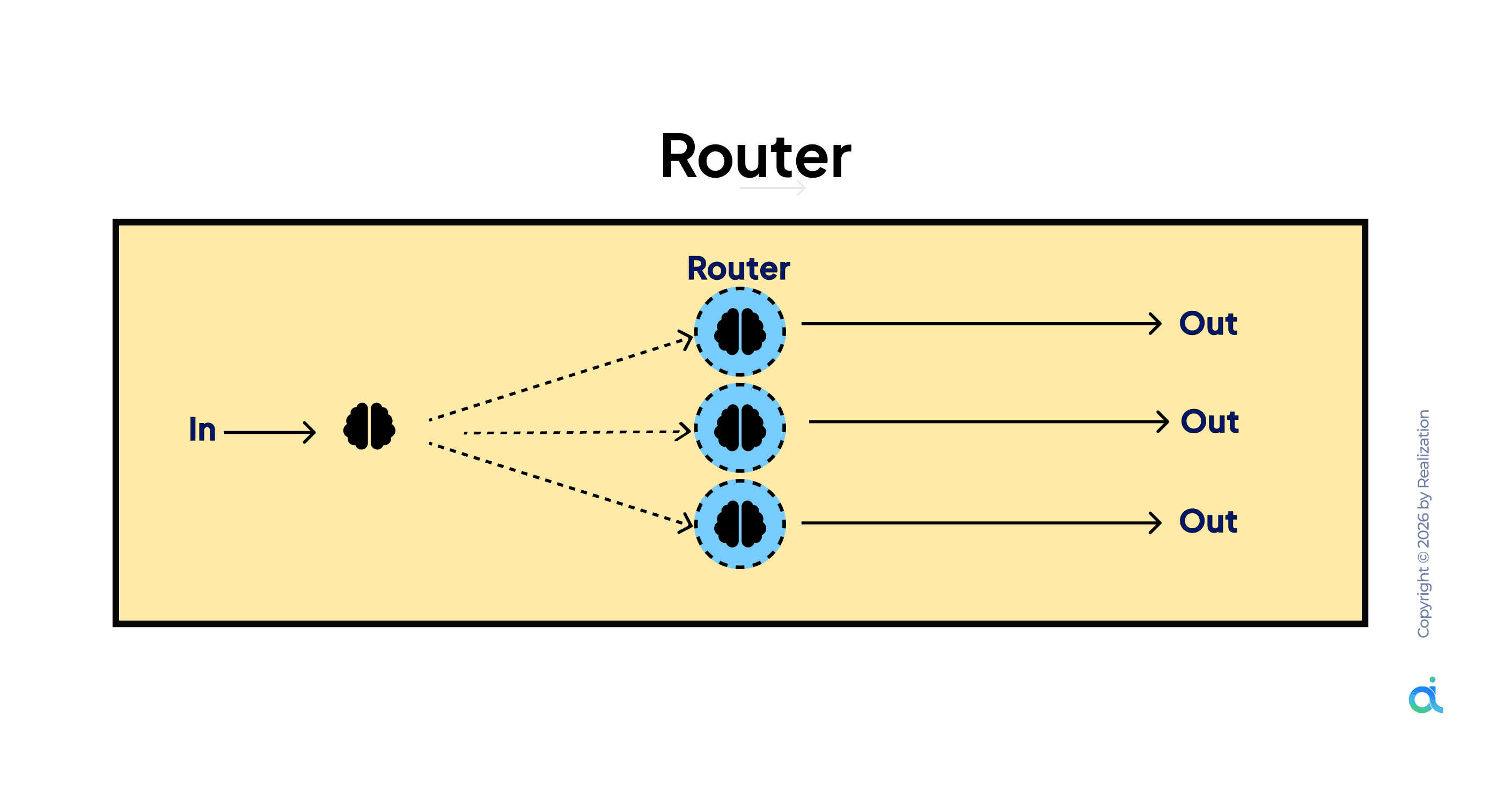
What it is: Routes incoming input to the right agent or workflow based on intent classification, rather than running all agents on all inputs.
How it works:
- Input arrives at a Router agent
- Router classifies intent or task type
- Based on classification, input is directed to the appropriate specialist agent or workflow
- Each agent produces its own output independently
Best suited for:
- Support systems with multiple categories of queries
- Intent routing in conversational AI
- Multi-agent flows where different tasks require different models
- Personalization systems that adapt to user context
When to use it: When you have multiple specialized agents and sending every input to all of them would be wasteful, slow, or produce conflicting outputs. The router is the decision layer that makes multi-agent systems practical at scale.
When not to use it: When classification itself is too ambiguous or expensive. If routing errors are costly, add a fallback path or human review tier.
5. Autonomous Workflow
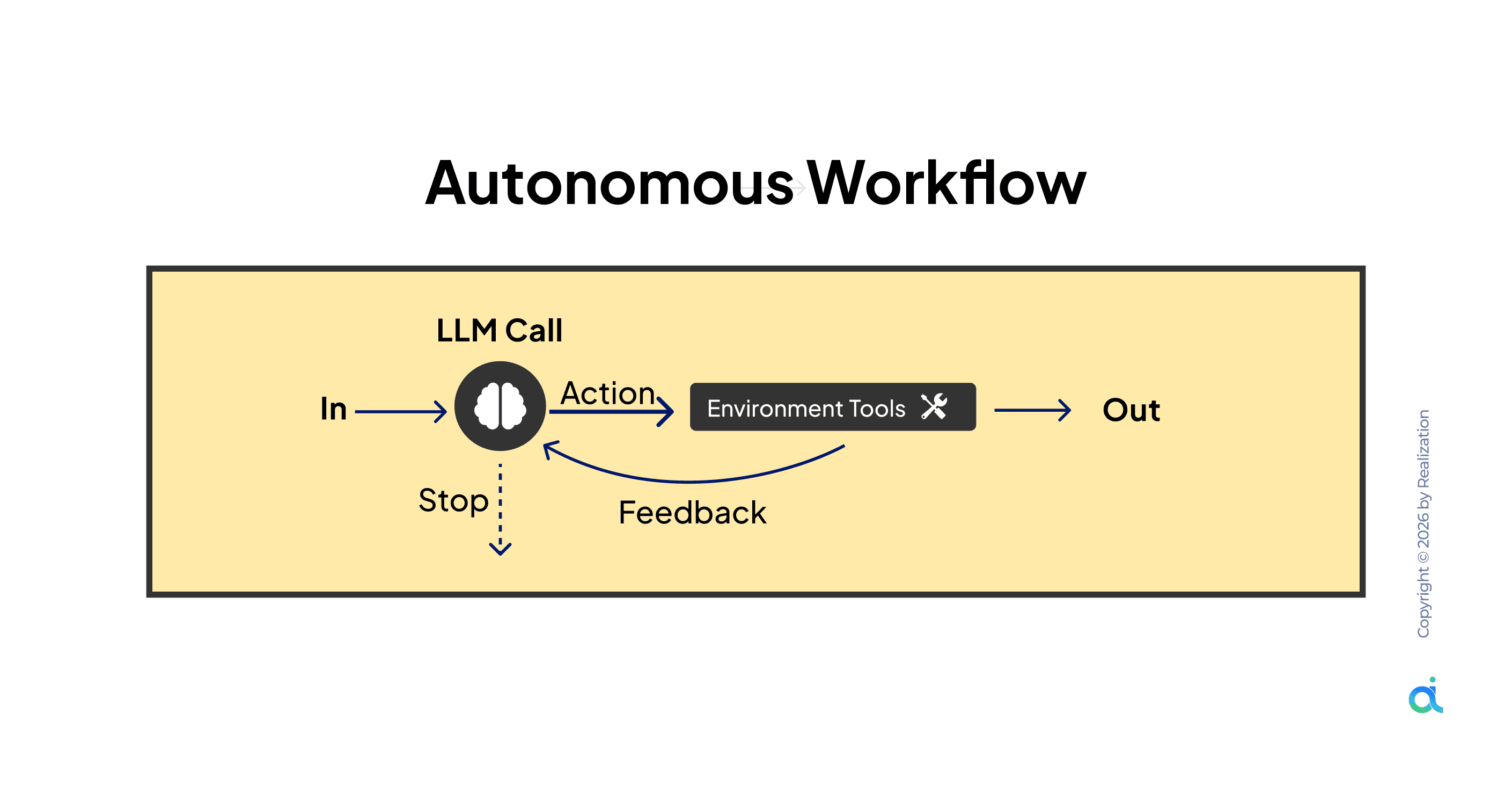
What it is: An agent acts, observes the result, and uses that feedback to improve its next action, running in a continuous loop until a stop condition is met.
How it works:
- Input triggers the agent
- The agent takes an action using the environment tools
- Environment returns feedback (success, failure, partial result)
- Agent observes feedback and decides: continue, adjust, or stop
- Loop runs until the task is complete or the stop condition is triggered
Best suited for:
- Autonomous agents operating without human-in-the-loop
- Computers use agents that interact with UIs and web browsers
- Task loops requiring trial-and-error refinement
- Simulations and environment-based testing
When to use it: When the task is too dynamic to script, but has a clear success condition the agent can evaluate itself. This is the pattern that powers Claude Code's /loop command run until tests pass.
When not to use it: When failure modes are costly and irreversible. Autonomous loops need well-defined stop conditions and rollback capability. Without them, they run indefinitely or make compounding errors.
6. Reflexion
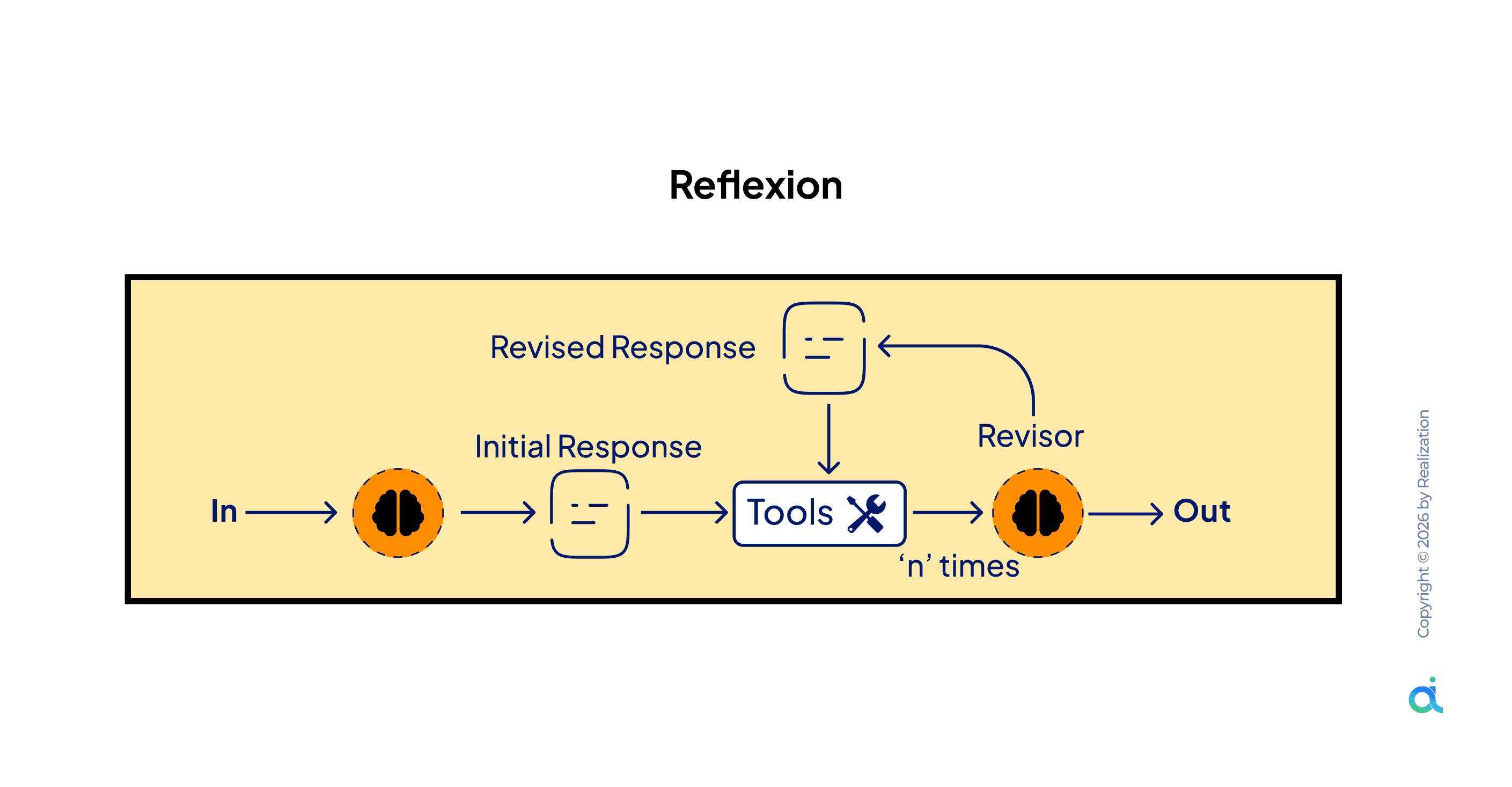
What it is: The agent generates an initial response, passes it through a Revisor that critiques and rewrites it, and repeats this cycle up to n times until quality criteria are met.
How it works:
- Input produces an Initial Response
- Response passes to a Tools layer for evaluation (tests, checks, criteria)
- A Revisor agent critiques the output and generates a Revised Response
- The revised response re-enters the loop
- Process repeats n times or until the quality threshold is met
Best suited for:
- Self-correction on complex reasoning tasks
- Quality control pipelines requiring iterative refinement
- Monitoring systems that need to verify their own outputs
- Iterative tasks where first-pass quality is predictably insufficient
When to use it: When you know the first output won't be good enough, and you want the system to improve itself rather than requiring human iteration. The Reflexion pattern is what the Claude Code 3-iteration code review loop implements.
When not to use it: When n iterations can explode the cost without a diminishing-returns ceiling. Always define a maximum iteration count and a fallback if the quality threshold isn't met.
7. ReWOO (Reasoning Without Observation)
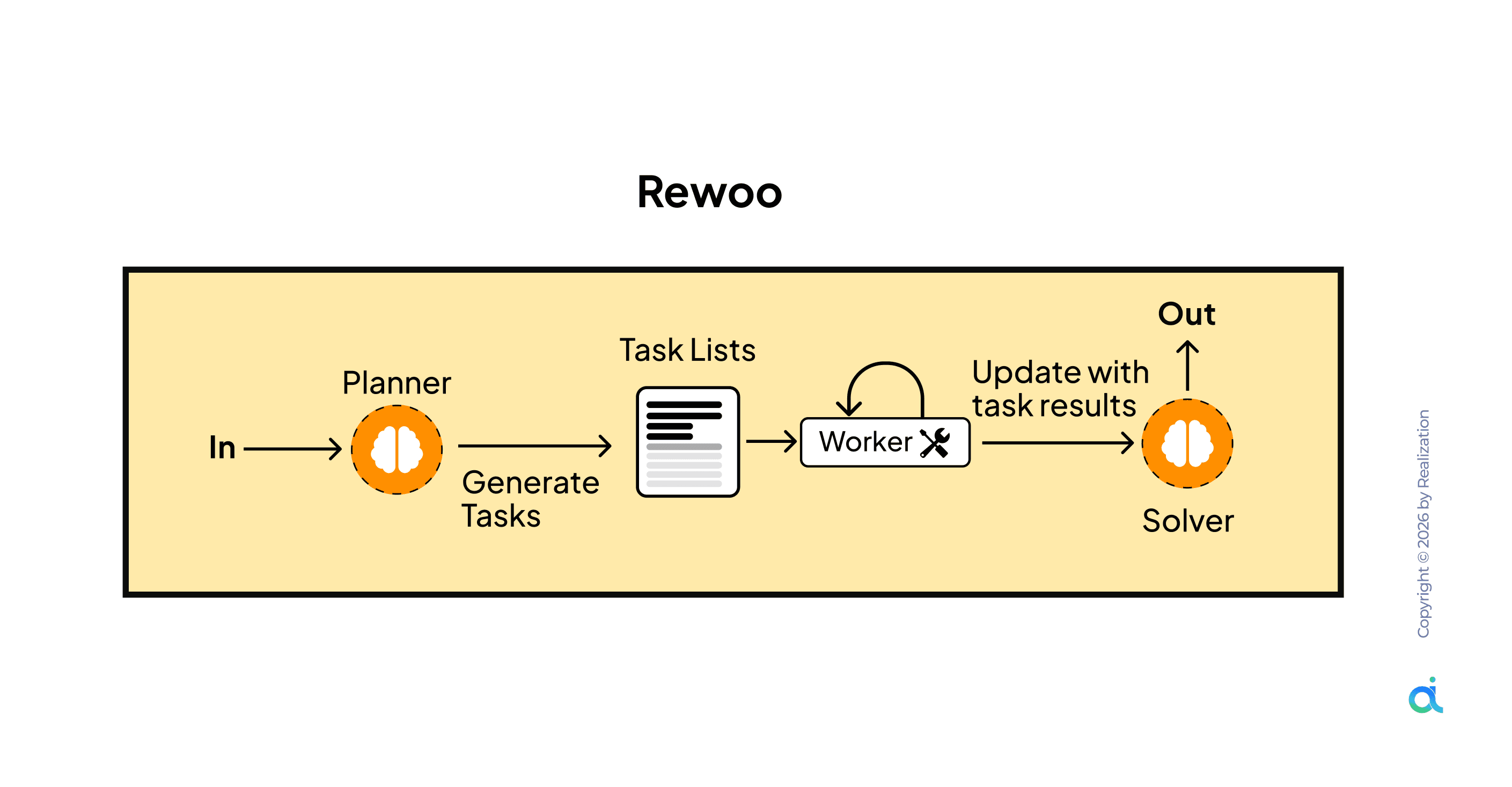
What it is: Plans the full task sequence first, then executes tasks in order, updating a shared context as each task completes, feeding results into the final solver.
How it works:
- Planner receives input and generates a full Task List upfront
- The worker executes tasks sequentially in the defined order
- Each task result updates the shared context
- After all tasks are complete, Solver synthesizes results into the final output
Best suited for:
- Research tasks requiring structured information gathering
- Multi-step Q&A with dependent sub-questions
- Structured problems where planning reduces wasted execution
- Knowledge queries spanning multiple sources
When to use it: When you can reason about the full task structure before any execution begins. ReWOO is more efficient than Reflexion for structured tasks because it front-loads the planning cost and eliminates redundant iterations.
When not to use it: When the task is too dynamic to plan upfront, if early results change what later steps need to do, ReWOO's static plan becomes a liability. Use Autonomous Workflow instead.
8. Plan and Execute
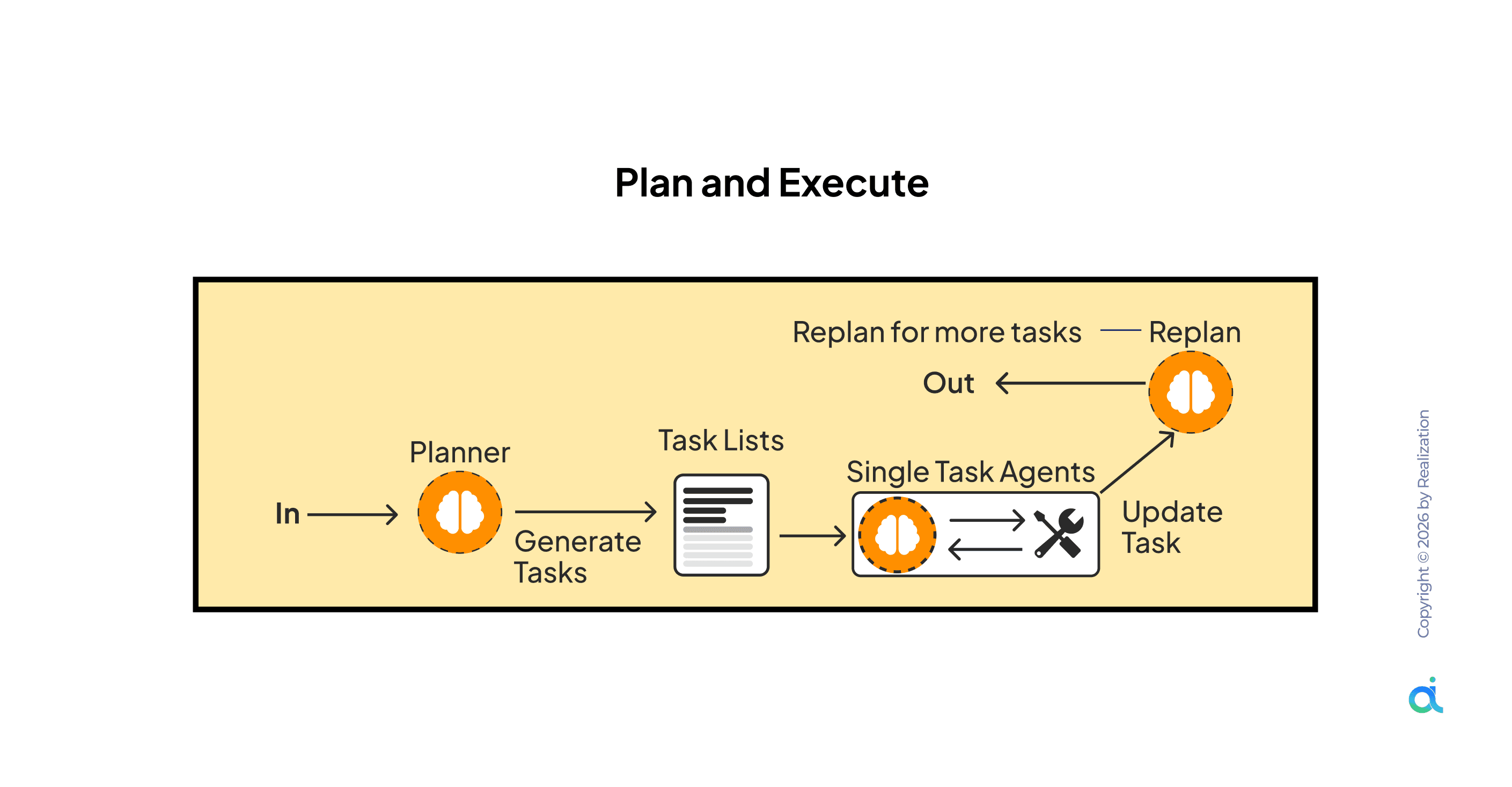
What it is: Creates a plan, executes tasks through single-task agents, and replans dynamically when results require it, combining upfront structure with adaptive execution.
How it works:
- Planner generates initial Task List
- Single Task Agents execute individual tasks
- Each agent can trigger an Update Task if results deviate from the plan
- When updates require broader changes, a Replan loop fires
- Final output is produced when all tasks are completed successfully
Best suited for:
- Automation workflows with variable complexity
- Data workflows where intermediate results affect downstream steps
- Task orchestration requires both planning and adaptability
- Process management across multiple systems
When to use it: When ReWOO is too rigid, but the full Autonomous Workflow is too unconstrained. Plan and Execute is the middle path, structured where possible, adaptive where necessary. It's the pattern most enterprise workflow automation tools are converging on.
When not to use it: Simple tasks that don't justify the planning overhead. The replan mechanism adds latency only worth it when task complexity genuinely warrants it.
What This Means for Enterprise AI Strategy
The reason these patterns matter at the leadership level:
- Budget conversations change. LLM cost is not a flat per-query fee it's determined by how many calls run per task, whether they're parallel or sequential, and whether feedback loops are bounded. Workflow architecture is cost architecture.
- Build vs. buy decisions shift. Understanding which pattern your vendor is using tells you more about the product's real capabilities and limitations than any benchmark. Ask which workflow pattern their agentic feature runs on. You'll learn a lot from whether they can answer.
- Failure modes become predictable. Each pattern fails in specific, knowable ways. Autonomous workflows run forever without stop conditions. Parallelization aggregation fails under high output variance. Prompt chains break when gate logic is too strict or too loose. Knowing the pattern means knowing where to look when something goes wrong.
Further Resources
Agentic AI Foundations
- anthropic.com/research Anthropic's published research on agentic systems
- deepmind.Google/research DeepMind's work on agent architectures
- arxiv.org/abs/2309.02427 ReAct: Synergizing Reasoning and Acting in Language Models
Frameworks for Building Agentic Workflows
- langchain.com LangChain and LangGraph for workflow orchestration
- llamaindex.ai LlamaIndex for RAG and agentic pipelines
- crewai.com CrewAI for multi-agent collaboration patterns
Enterprise AI Architecture
- docs.anthropic.com/en/docs/agents Anthropic's agent documentation
- openai.com/research OpenAI's work on reasoning and agent design
- microsoft.com/en-us/research/project/autogen AutoGen for multi-agent orchestration