

AI coding agents are moving from demos to production faster than most teams expected.
Tools like Claude Code can already navigate repositories, write production-ready code, run tests, and accelerate engineering workflows at an impressive level.
But once deployed at scale, teams quickly encounter issues with context retention, runaway token usage, unstable execution loops, and inconsistent behavior across long-running tasks.
Most organizations try to solve these problems with better prompts, when the real challenge is usually the missing infrastructure layer around the model, the harness responsible for memory, permissions, tooling, observability, and execution control.
What Is an Agentic Harness, Really?
The harness is everything that wraps the model. It is the infrastructure layer that manages orchestration, tooling, memory, and safety. It is the system that decides:
- What the agent is allowed to read, edit, and execute
- What context it carries and what it remembers across sessions
- How it handles multi-step workflows and task failures
- How tokens and budgets are managed to ensure scalability
In March 2026, Claude Code's source was accidentally exposed, revealing 500,000 lines of code that confirmed the harness, not the model, was the real differentiator. Harnessing accounts for up to 80% of AI project value by 2026. These six patterns are extracted from that architecture.
Pattern 1 Persistent Instruction File
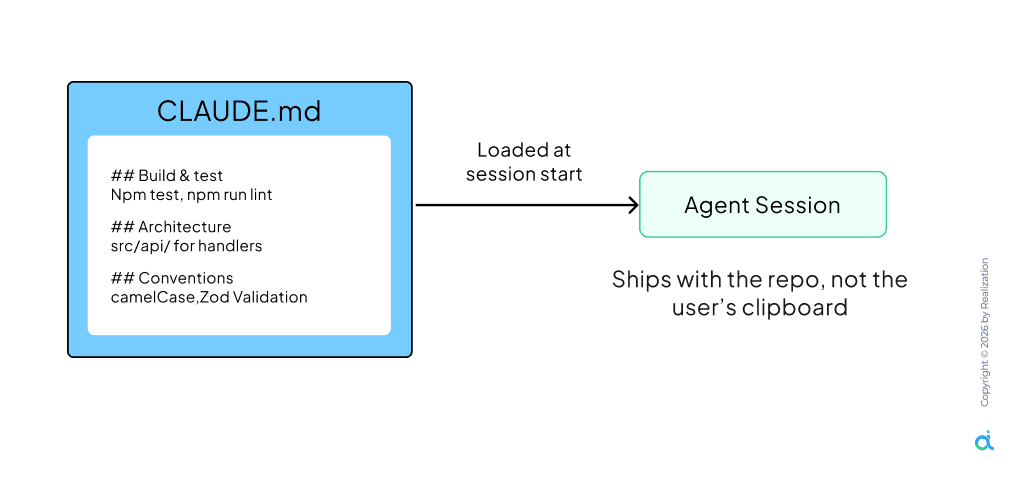
Without a persistent memory of your stack and conventions, every session starts blank. You repeat instructions, and the agent makes the same mistakes repeatedly. The solution is a CLAUDE.md file in your project root that loads automatically, defining build commands, naming standards, and architectural rules.
How does it work?
The file resides in source control, ensuring every developer on a distributed team is running a slightly different agent with different behaviors. It contains:
- Build and test commands (e.g., npm test)
- Directory-specific naming conventions and PascalCase/camelCase choices
- Lists of deprecated APIs or patterns to avoid
85% of enterprises are now customizing AI agents for specific workflows, making standardized instruction files a baseline for governance and consistency.
Why it matters
- Enforces team standards automatically for every developer
- Reduces repetitive prompting and onboarding friction
- Ensures consistent code reviews and outputs across a project
Pattern 2 Scoped Context Assembly
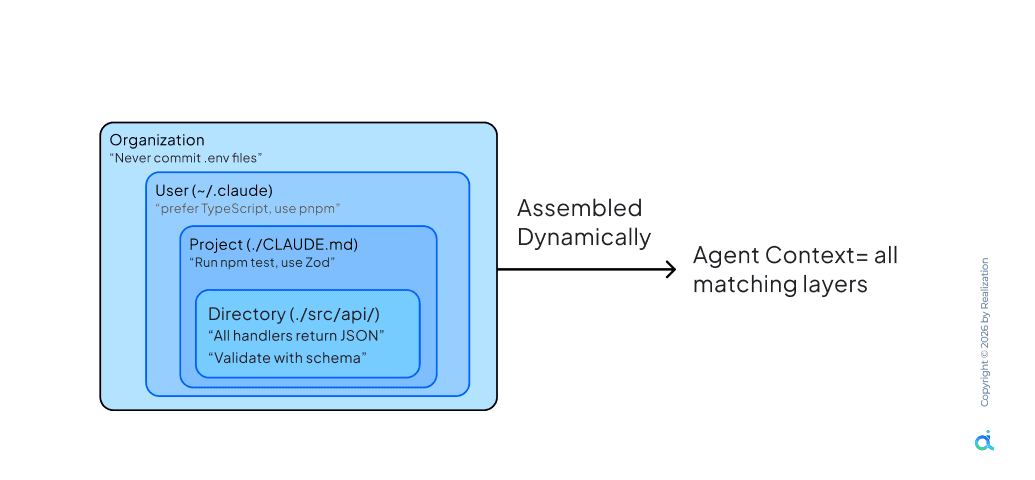
In large codebases, a single instruction file becomes a generic blob. Scoped assembly loads instructions dynamically based on where the agent is working, at the organization, project, or directory level.
How it works
- Organization Level: Universal rules applied across every project in the enterprise
- User Level (~/.claude): Individual developer preferences following them across project borders
- Directory Level (./src/api/): Module-specific rules that don't collide with UI conventions
Cons to know
- Discoverability becomes harder as instruction files multiply
- Conflicting rules across scopes can produce hard-to-trace behavior
Pattern 3: Tiered Memory
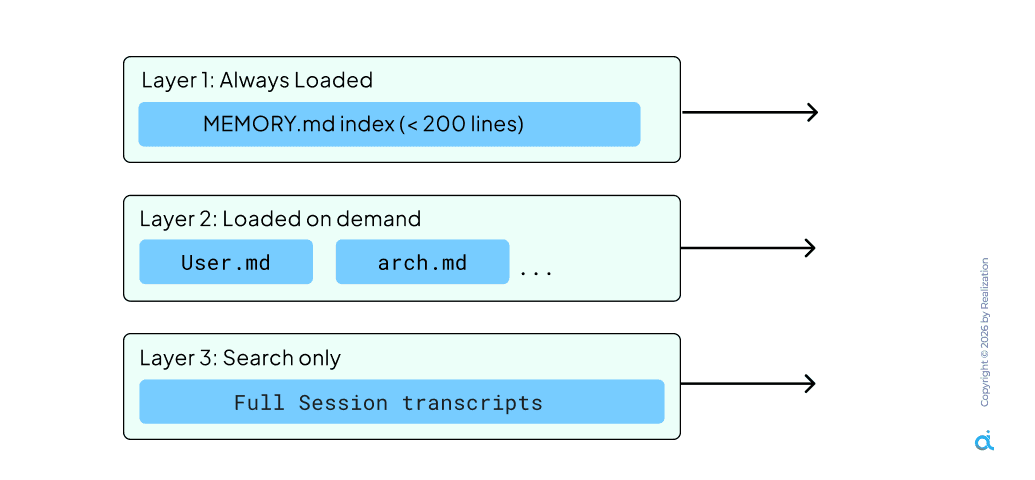
Loading all history into every session wastes tokens and hits context limits. Tiered memory organizes facts into Layer 1 (Always Loaded), Layer 2 (On-Demand), and Layer 3 (Search-Only).
How it works
- Layer 1: Always Loaded: A capped MEMORY.md index of essential working memory. This keeps the agent focused on core project facts every session.
- Layer 2: Loaded on Demand: Topic files like arch.md or decisions.md that only load when the current task matches the domain, saving significant token costs.
- Layer 3: Search Only: Historical transcripts indexed on disk, retrieved only when explicitly relevant to past context.
For long-running agents that can execute tasks for 24-50+ hours, this tiered architecture prevents plan drift and task abandonment by managing context quality.
Pattern 4: Dream Consolidation
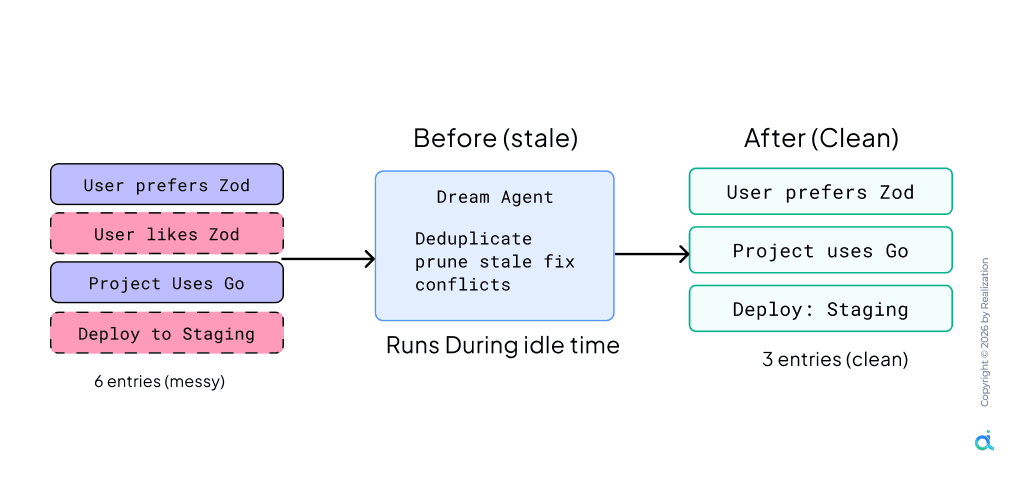
As sessions accumulate, memory files fill with duplicates and contradictions. A background process named autoDream in the leaked source automatically reviews and deduplicates memory.
How it works
- Deduplicate: Merge entries expressing similar preferences into single, actionable points
- Prune: Remove stale facts superseded by newer architectural decisions
- Conflict Resolution: Surface and resolve contradictions rather than letting both persist
Why it matters
- Prevents Context Decay: Ensures the agent is fed accurate, non-conflicting information after months of usage
- Token Efficiency: Compressed memory files mean more "reasoning room" for actual tasks in every session start
Pattern 5: Context-Isolated Subagents
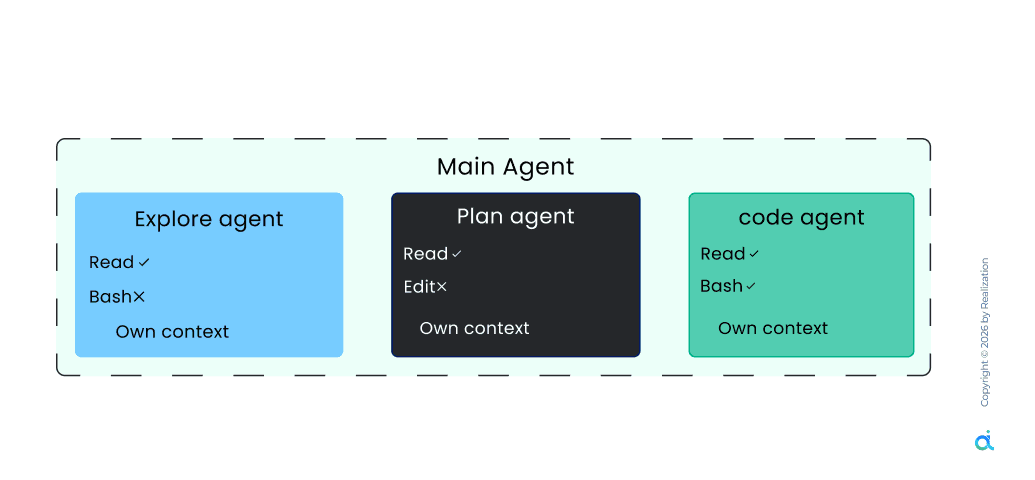
When one agent explores, plans, and writes in one window, context noise builds. This pattern decomposes tasks into phases, each handled by a specialized subagent with an isolated context.
How it works
- Planner Agent: Decomposes the task into a structured plan without the noise of previous execution history
- Generator Agent: Writes the code based strictly on the isolated plan context
- Evaluator Agent: A skeptical reviewer who critiques output robustly before completion
Task isolation ensures high reliability on complex enterprise workflows like security audits or migrations, where context bleed leads to degradation.
Pattern 6: Fork-Join Parallelism
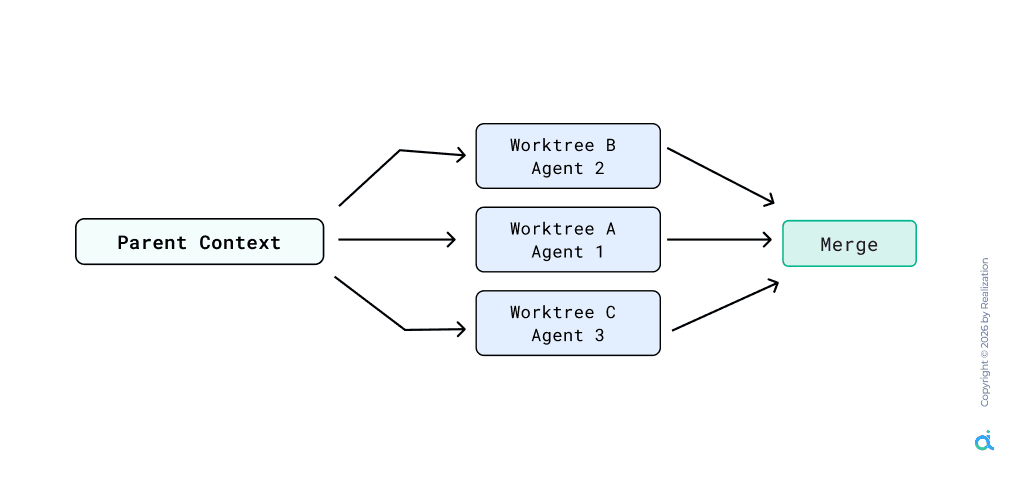
Sequential execution is a bottleneck. Fork-join parallelism forks a parent context into multiple independent worktrees for agents to work concurrently on parts of a task.
How it works
- Independent Worktrees: Separate agents run on different modules simultaneously via git worktrees
- Swarm Orchestration: Auto-spinning up teams of up to 100 sub-agents for massive tasks
- Join/Merge: The parent context merges parallel results once all agents finish their independent phases
Pros
- Closes the gap between theoretical AI power and delivered enterprise throughput
- Reduces time-to-delivery for quarter-long projects from months to days
- Measurable ROI for Teams/Max tiers where rate limits are high enough for parallel runs
The full build order
- Week 1: Baseline Identity. Create CLAUDE.md with build/test commands and foundational architectural rules
- Week 2: Scoped Assembly. Add directory-level instructions for high-complexity packages in your monorepo.
- Week 3: Memory Tiers. Classification of facts into layers; move non-essential items to demand-only or search-only storage.
- Month 2: Context Isolation. Decompose recurring tasks into explore/plan/execute phases with isolated contexts.
- Month 3: Consolidation & Parallelism. Enable background dreaming for memory pruning and scale parallel sub-agents for throughput.
Conclusion
The harness is infrastructure, and infrastructure compounds. Enterprise teams getting mission-critical results aren't running better models than everyone else; they've built the layer around the model that makes it reliable, predictable, and safe.
Start with the foundational instruction file, build your tiers, and watch the transformation over the next quarter.